청크 서버 노드가 '실패' 상태입니다 팔로우

증상
다음 증상 중 일부 또는 전부가 확인됩니다.
● WebCP에서 일부 노드 또는 디스크는 FAILED로 표시되고 스토리지 아이콘은 빨간색으로 표시됩니다.
● vstorage -c <clustername> top 명령의 출력에서 일부 CS는 실패 상태에 있습니다.
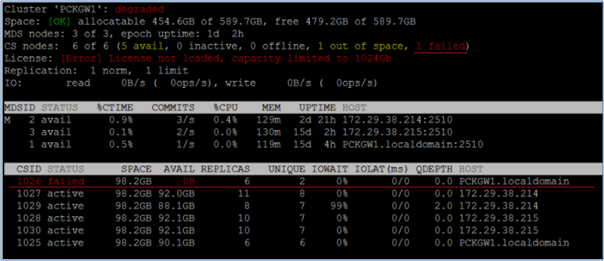
● vstorage -c <clustername> get-event 출력에 다음 이벤트 중 하나 이상이 있습니다.
MDS WRN: CS#1025 have reported IO error on pushing chunk 1cee of 'data.0', please check disks
MDS ERR CS#1026 detected back storage I/O failure
MDS ERR CS#1026 detected journal I/O failure
MDS WRN: Integrity failed accessing 'data.0' by the client at 192.168.1.11:42356
MDS WRN: CS#1025 is failed permanently and will not be used for new chunks allocation
원인
디스크에서 I/O 오류가 반환되면 이 디스크에 있는 청크 서버는 '실패'상태로 전환됩니다. Acronis Cyber Infrastructure는 스토리지 노드 재부팅 후에도 이 상태에서 CS를 자동으로 복구하지 않습니다.
I/O 오류가 발생한 직후 파일 시스템은 읽기 전용 모드로 다시 마운트 되고 Acronis Cyber Infrastructure는 더 이상이 CS에 데이터 청크를 할당하지 않습니다. 동시에 드라이브를 읽을 수 있는 경우 Acronis Cyber Infrastructure는 드라이브에서 모든 청크를 복제하려고 합니다.
해결 방법
문제를 해결하려면 다음 워크 플로를 사용하는 것이 좋습니다.
1. 영향을 받는 디스크를 확인합니다.
2. 건강 상태를 확인하십시오.
3. 기기를 교체해야 하는지 결정합니다.
4. 위의 정보를 바탕으로 실패한 CS를 활성 상태로 되돌 리거나 해제합니다.
1. 영향을 받는 장치 확인
WebCP 사용 :
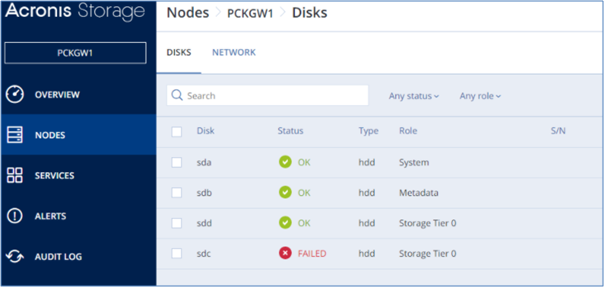
하여 영향을 받는 노드 및 드라이브를 찾는 방법 왼쪽 메뉴에서 Nodes로 이동하여 Failed로 표시된 노드를 클릭합니다. 이 노드의 이름을 기록해 둡니다. 디스크를 클릭하고 실패로 표시된 디스크를 찾으십시오. 이 디스크의 장치 이름을 기록합니다 (예 :이 스크린 샷의 SDC).
SSH 및 CLI를 사용하여 영향을 받는 디스크를 찾는 방법 :
SSH를 사용하여 Acronis Cyber Infrastructure 클러스터의 노드에 로그인합니다.
다음 명령을 실행하십시오.
vstorage -c <cluster_name> stat | grep failed
출력 예시 :
[root@ ~]# vstorage -c PCKGW1 stat | grep failed
connected to MDS#2
CS nodes: 6 of 6 (5 avail, 0 inactive, 0 offline, 1 out of space, 1 failed), storage version: 122
1026 failed 98.2GB 0B 6 2 0% 0/0 0.0 172.29.38.210 7.5.111-1.as7
첫 번째 열에 표시된 CS ID (위의 예에서는 1026)와 CS가 있는 노드의 IP 주소 (위의 예에서는 172.29.38.210)가 표시됩니다.
영향을 받는 노드에 로그인하십시오.
영향을 받는 CS가 있는 디스크를 확인하려면 다음 명령을 사용하십시오.
vstorage -c <cluster_name> list-services
출력 예시 :
(!) CS가 실패한 상태이지만 가능하면 다른 CS로 데이터를 복제하고 실행 중입니다. 따라서 list-services 명령의 출력에서 활성으로 표시됩니다.
[root @ PCKGW1 ~] # vstorage -c PCKGW1 list-services
TYPE ID ENABLED STATUS DEVICE/VOLUME GROUP DEVICE INFO PATH
CS 1025 enabled active [1297] /dev/sdd1 VMware Virtual disk /vstorage/df218335/cs
CS 1026 enabled active [1288] /dev/sdc1 VMware Virtual disk /vstorage/12bb6baf/cs
MDS 1 enabled active [1295] /dev/sdb1
2. 영향을 받는 디스크 상태 확인
이 단계의 궁극적인 목표는 영향을 받는 디스크를 계속 사용할 수 있는지 또는 교체해야 하는지 여부를 결정하는 데 필요한 정보를 수집하는 것입니다.
문제와 관련된 모든 데이터에 대해 다음 정보를 검토하고 분석해야 합니다.
● dmesg 명령 출력. 사람이 읽을 수 있는 타임스탬프를 보려면 dmesg -T를 사용하는 것이 편리합니다.
● /var/log/messages 파일
● 물리적 하드 드라이브의 SMART 상태. 다음으로 획득할 수 있습니다 : smartctl -a <영향을 받는 장치>
3. 기기 교체가 필요한지 결정
물리적 스토리지 유형 (직접 연결된 JBOD, iSCSI LUN, 파이버 채널 등) 및 특정 상황에 따라 e xact 오류 메시지 및 패턴이 크게 다릅니다.
다음은 의사 결정 과정을 촉진하기 위한 몇 가지 경험 규칙입니다.
● SMART 상태가 물리 디스크에 대해 만족스럽지 않은 경우 일반적으로 디스크를 교체해야 함을 의미합니다.
● 이 디스크에 대해 유사한 문제 또는 기타 오류 메시지가 이전에 기록되었는지 확인합니다. 문제가 처음으로 나타나면 일반적으로 구성 변경 없이 CS를 재사용 할 수 있습니다. 그럼에도 불구하고 앞으로 이 CS에 특별한 관심을 기울이십시오.
● 단일 백플레인 또는 RAID 컨트롤러의 여러 디스크에 대해 dmesg 및 / 또는 / var / log / messages에 여러 오류 메시지가 있는 경우 이는 하드웨어 자체가 원인 일 수 있음을 의미합니다. 추가 검토는 하드웨어 공급 업체에 문의하십시오.
● iSCSI 장치의 경우 모든 I / O 오류는 네트워크 연결 불량 또는 잘못된 네트워크 구성의 결과 일 수 있습니다. 문제 해결은 철저한 네트워크 확인으로 시작해야 합니다.
● Acronis Cyber Infrastructure가 가상 머신에 설치되어 있고 CS가 NAS에 저장된 .vmdk 또는 .vhd 파일에 있는 경우 프로덕션으로 이동하기 전에 이러한 시스템의 안정성을 주의 깊게 확인해야 합니다. Acronis Cyber Infrastructure는 정전과 같은 긴급 상황에서 스토리지 장치가 데이터를 디스크로 플러시 하는 방법을 확인하기 위한 특수 도구인 vstorage-hwflush-check를 제공합니다. 이 도구를 사용하여 전원이 꺼진 경우 스토리지가 올바르게 작동하는지 확인하는 것이 좋습니다. 이 문서에서는 도구 사용 방법을 설명합니다.
4. 실패한 CS를 활성 상태로 되돌립니다.
동일한 드라이브에서 동일한 CS를 재사용하기로 결정한 경우 아래 단계를 따르십시오.
● 영향을 받는 Acronis Cyber Infrastructure 노드를 재부팅합니다.
● dmesg | grep <disk name> 영향을 받는 드라이브의 파일 시스템 오류에 대한 모든 메시지 확인. 오류가 발생하면 fsck 또는 e2fsck로 파일 시스템을 확인하십시오.
CS를 위해 할당된 디스크의 파일 시스템을 확인하는 방법
○ storage -c <cluster_name> list-services 명령을 사용하여 해당 CS의 디스크 이름과 마운트 경로를 확인합니다.
○ 다음을 사용하여 CS 서비스를 중지하고 비활성화합니다.
systemctl stop vstorage-csd. <cluster_name>. <CSID> .service
systemctl disable vstorage-csd. <cluster_name>. <CSID> .service
○ 다음을 사용하여 CS 디스크의 파일 시스템을 마운트 해제합니다.
umount -l <마운트 경로>
위의 예에서 다음 경로는 영향을 받는 CS에 대해 list-services 명령에 의해 반환됩니다. / vstorage / 12bb6baf / cs
이 경우 다음 umount 명령을 사용해야 합니다.
umount -l / vstorage / 12bb6baf /
○ 다음으로 파일 시스템 검사 시작
fsck <disk_name> (예 : 위의 예에서 fsck / dev / sdc1)
○ 파일 시스템이 확인되고 마운트 파티션이 다시 고정되면 :
mount <disk_name> <마운트 경로> (예 : mount / dev / sdc1 / vstorage / 12bb6baf /)
○ CS 서비스 활성화 및 시작
systemctl enable vstorage-csd. <cluster_name>. <CSID> .service
systemctl start vstorage-csd. <cluster_name>. <CSID> .service
○ 결과 확인
systemctl status vstorage-csd. <cluster_name>. <CSID> .service
vstorage -c <cluster_name> top
● 다음 명령을 사용하여 CS에 대한 실패 상태를 대체하십시오.
vstorage -c <cluster_name> rm-cs -U <CSID>
● 다음 명령을 사용하여 CS의 활성 상태를 확인하고 확인합니다.
vstorage -c <cluster_name> stat | grep <CSID>
참조 - https://kb.acronis.com/content/60632